ML13 | 用tf官方的预训练模型-语音识别
Javascript玩转机器学习13
语音识别
- 模型接受声音信息,输出分类信息
- 声音在计算机里是声谱图,因此也可以使用卷积神经网络
加载预训练语音识别模型(tf官网的模型)
- 开本地静态服务器,获取语音识别模型文件
- 使用tfjs-models的speech-commands包加载模型 (tfjs-models是tf官方的模型库)
进行语音识别
- html
<script src="script.js"></script>
<style>
#result > div {
float: left;
padding: 20px;
}
</style>
<div id="result"></div>- js
// 引入tf-models库提供的语音命令npm包
import * as speechCommands from "@tensorflow-models/speech-commands";
//本地静态文件服务器地址
const MODEL_PATH = "http://127.0.0.1:8080/speech";
window.onload = async () => {
// speechCommands文档:
// https://github.com/tensorflow/tfjs-models/tree/master/speech-commands
const recognizer = speechCommands.create(
"BROWSER_FFT", //傅里叶变换
null,
MODEL_PATH + "/model.json",
MODEL_PATH + "/metadata.json",
);
//加载模型
await recognizer.ensureModelLoaded();
//显示模型能识别的语音类型
const labels = recognizer.wordLabels().slice(2);
const resultEl = document.querySelector("#result");
resultEl.innerHTML = labels
.map(
(l) => `
<div>${l}</div>
`,
)
.join("");
//浏览器监听语音
recognizer.listen(
(result) => {
const { scores } = result;
const maxValue = Math.max(...scores);
//拿到分类中 可能性最大的单词
const index = scores.indexOf(maxValue) - 2;
//突出显示
resultEl.innerHTML = labels
.map(
(l, i) => `
<div style="background: ${i === index && "green"}">${l}</div>
`,
)
.join("");
},
{
overlapFactor: 0.3, //识别频率
probabilityThreshold: 0.9, //准确度阈值,超过0.9的准确度 就执行参数一的函数
},
);
};效果
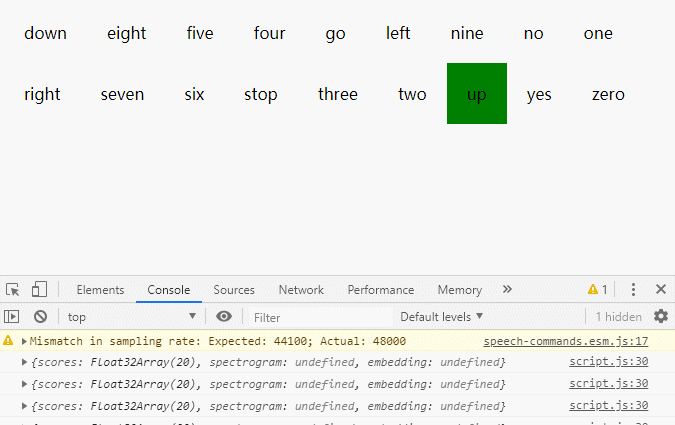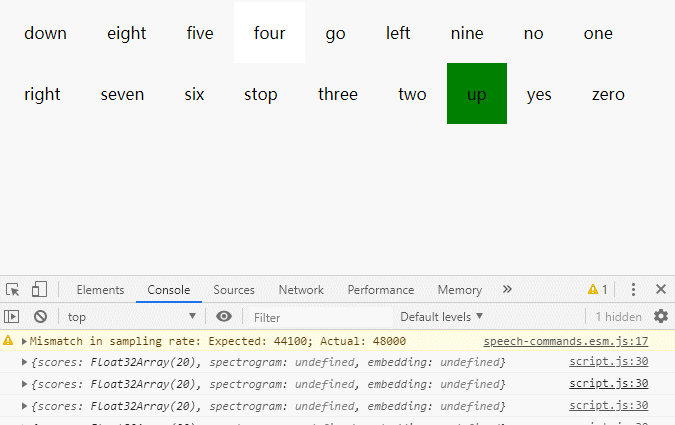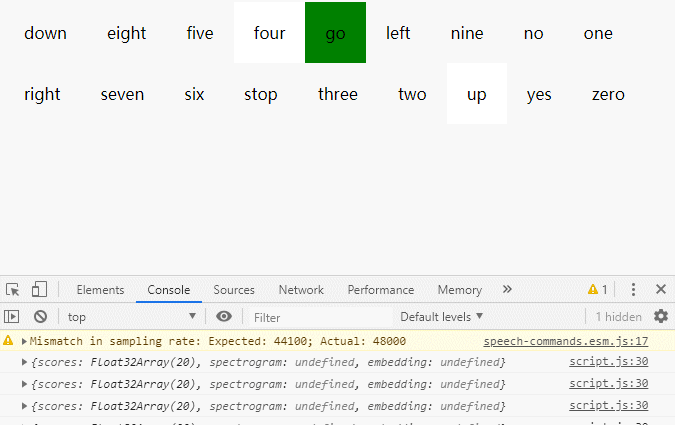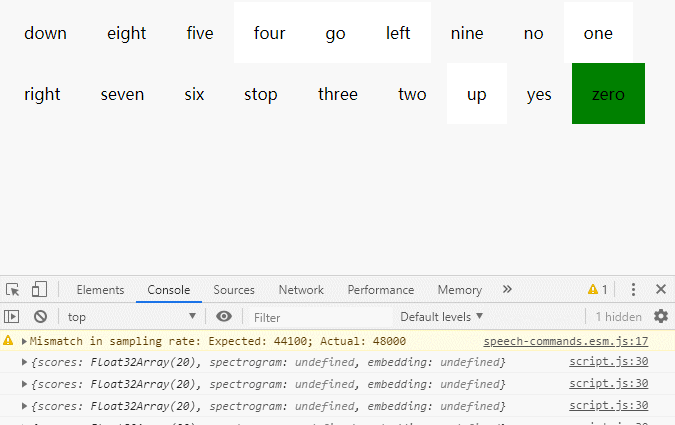
上次更新: